Building a Triple-Reasoning Chat Analyzer
I am taking IDH3600 with Professor Prevaux, a course on AI ethics course and kept coming back to one question: do LLMs actually reason, or do they just pattern-match their way to a confident-sounding answer?
The course covered deductive, inductive, and abductive reasoning as distinct modes of argument. And I started wondering: if you forced an LLM to follow each structure explicitly, would the outputs actually differ? Would the reasoning style change what information gets surfaced, what gets emphasized, what gets left out?
I decided to build something to find out.
The Approach: Three Prompts, Three Reasoning Styles
IDH3600 introduced classical logic as a framework for understanding how arguments are structured. Professor Prevaux covered three patterns that became the backbone of this project:
- Deductive: start from universal principles, apply them to the specific case, reach a necessary conclusion. If the premises are true, the conclusion must be too.
- Inductive: gather specific examples, identify patterns, generalize cautiously. The conclusion is probable, not certain.
- Abductive: observe the phenomenon first, then reason backwards to the most likely explanation. The classic "inference to the best explanation."
I wanted to see them in action side by side. The idea: send the same question to an LLM three times, each time with a prompt that forces a different reasoning structure, and compare what comes back.
Each prompt instructs the model to follow the structure explicitly: use syllogistic form for deductive, reference at least two real examples for inductive, state the observation before the explanation for abductive.
This is pseudo-reasoning simulation. LLMs are fundamentally statistical pattern matchers. They don't actually reason in the classical sense. The prompts force the model to simulate these patterns, which is educational, but not the same as a system that genuinely reasons from first principles. This distinction came up repeatedly in IDH3600.
How It Works
The stack is React + TypeScript on the front, Node.js + Express on the back, deployed via Docker.
When you send a message, the backend fires three parallel requests to OpenRouter (using Llama 3.3 70B by default). Each request gets a different system prompt with detailed structural instructions, down to sentence count, connector words to use, and how to acknowledge uncertainty. The three responses come back and render side by side.

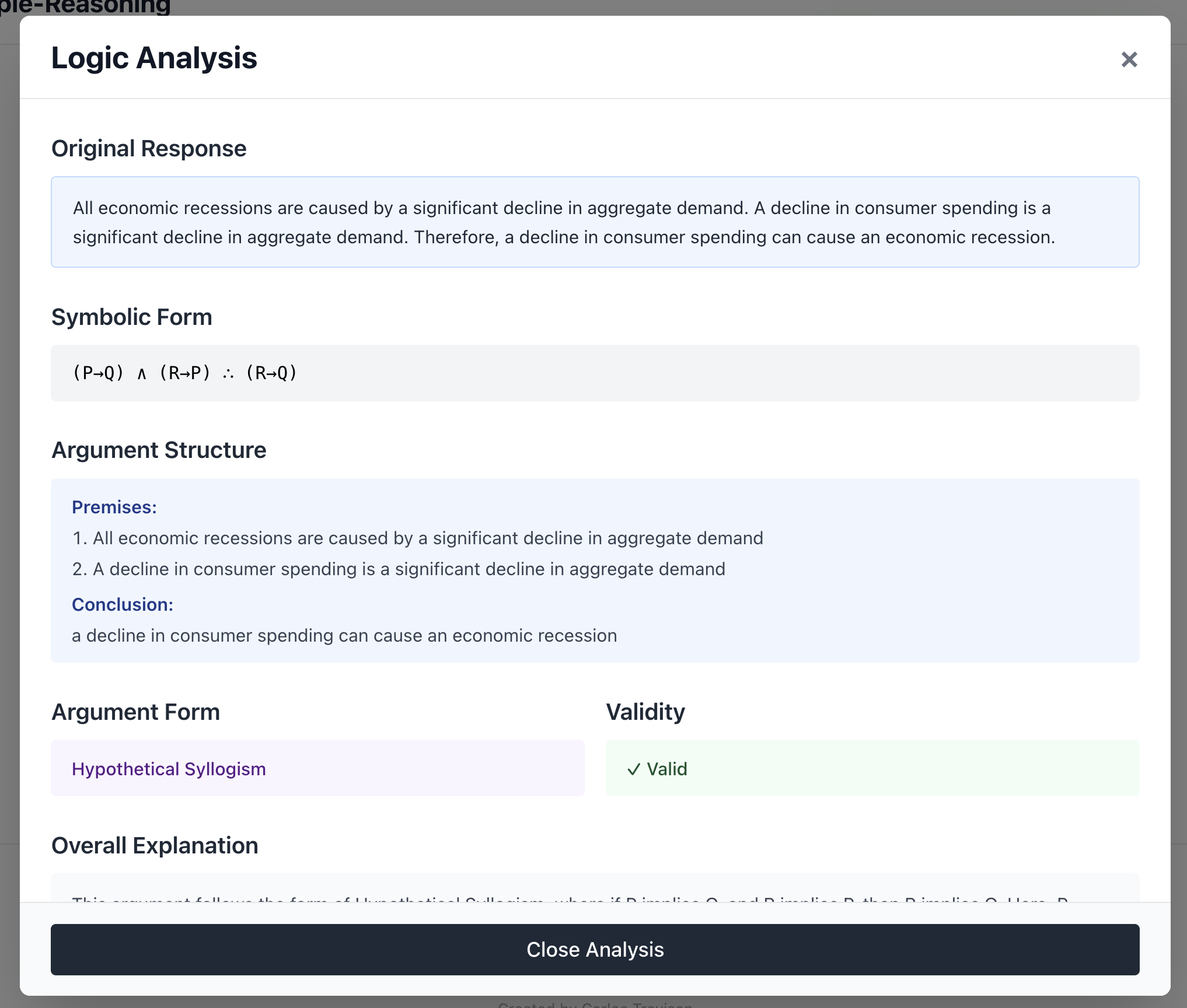
There's also a logic analysis feature. Click "Analyze Logic" on any response and the backend sends that text back to the model with a different prompt: extract the symbolic form, identify the argument structure, check for logical fallacies, assess validity. It returns structured JSON that renders as a clean breakdown: symbolic notation, premises, conclusion, any fallacies detected with corrections.
The first page includes response structure guidelines showing exactly what each reasoning type should look like, so you can evaluate whether the model actually followed the pattern. Useful for classroom discussion.
Deployment uses Docker Hub and nginx as a reverse proxy with HTTPS via Let's Encrypt. The frontend is built with the API URL baked in at build time via a Docker ARG, which meant rebuilding any time the domain changed. A lesson I learned the hard way after the /api path doubled up in the URL.
What I Learned
The most interesting finding was how much framing shapes content. Ask the same question three ways and you get genuinely different information surfaced. The inductive response cites examples the deductive one never mentions. The abductive one often surfaces a mechanism the other two skip past entirely.
It also made the limitations of LLMs more concrete. Sometimes a response labeled "deductive" is really just inductive in disguise. The model gestures at a general principle but then reasons from examples.
Prompt engineering did more heavy lifting than model selection. Getting the model to commit to a structure, not just mention it, required very specific instructions about format, connectors, and what not to do.
The live version is at aiethics.carlostrevisan.xyz and the code is on GitHub.
Same question, three answers, three ways of thinking. Turns out that's often enough to see where the reasoning breaks down.